How To Write Wireshark Dissector
Let’s allow your protocol to be recognized in Wireshark
Sewio provides Wireshark Protocol Dissector Development Service.
We will create protocol dissector according to your specific needs as a plugin or as native part of Wireshark. Normally, you would need to develop your own protocol dissector quite rarely, so learning the dissector development from the scratch might be not very efficient way. Let’s put this development to our hands and gain from our expertise.


Partnering with Sewio reduced our development time when creating a Wireshark dissector tool for our wireless protocol, SNAP. Their level of expertise in analyzing and capturing 802.15.4 packets accelerated our time to market, eliminated unexpected complexities and provided our team with a very valuable tool.
Introduction
The main goal of this tutorial is to briefly explain the process of dissector creation for Wireshark. Dissector is simply a protocol parser. Wireshark contains dozens of protocol dissectors for the most popular network protocols. In case when some dissector needs to be adjusted or creation of completely new protocol dissector is desired, knowledge of dissector creation procedure might be very useful.
Wireshark & Ethereal Network Protocol Analyzer Toolkit book was used as the reference as well as the README.developer from wireshark/doc and official documentation page.
Here you can download the complete LWM dissector used in this tutorial
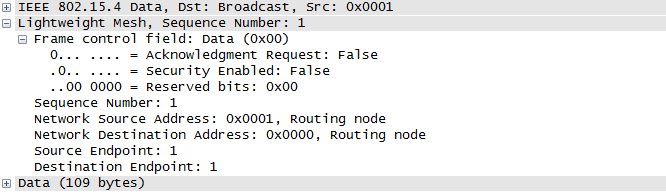
Let’s create our new Wireshark dissector. It will decode a new protocol stack called Lightweight Mesh (LWM 1.1.1) from Atmel. This software stack is used for a low power wireless mesh networking. LWM is based on the IEEE 802.15.4 standard. LWM frame structure is depicted in picture below.

IEEE 802.15.4 + LightWeight mesh frame fields
LWM consist of Network Header, Payload and MIC field. Let’s have a look to the field representation:
| Name of field | Size | Displayed |
| Frame control | 8 | Individual bits |
| Sequence number | 8 | Decimal number |
| Source address | 16 | Hexadecimal number |
| Destination address | 16 | Hexadecimal number |
| Source Endpoint | 4 | Decimal number |
| Destination Endpoint | 4 | Decimal number |
Here is a screenshot how we would like to see it in Wireshark:
Follow the dissector template
The Wireshark dissector template can be found here. There are several steps that need to be completed in order to integrate a new dissector into Wireshark. The first step is to add your modification comments. Remember that Wireshark is open-source code, so the main comments identifies not only what you have created, but also includes information about the original contributor of Wireshark.
When working with the template, you need to replace certain text with your information. For example, for line 1, you would replace packet-PROTOABBREV.c with packet-.c. Change line 2 (PROTONAME) to indicate the protocol your dissector is meant to decode. Line 3 should be modified with the copyright date, your name, and your e-mail address. Line 5 of the comment is important to the SVN system, as it identifies the current file intrusion detection (ID) and revision.This line is modified when source code is checked in and out of the SVN system; make sure you do not remove this line. Finally, line 11 should be modified to document the source code of your information used to build the dissector. If this information is not available or cannot be disclosed, this section can be omitted.The rest of the comments should remain intact to reflect the original author (Gerald Combs) and the GPL information.
/* packet-PROTOABBREV.c
* Routines for PROTONAME dissection
* Copyright 2000, YOUR_NAME
*
* $Id: README.developer,v 1.86 2003/11/14 19:20:24 guy Exp $
*
* Wireshark – Network traffic analyzer
* By Gerald Combs <gerald@wireshark.org>
* Copyright 1998 Gerald Combs
*
* Copied from WHATEVER_FILE_YOU_USED (where “WHATEVER_FILE_YOU_USED”
* is a dissector file; if you just copied this from README.developer,
* don’t bother with the “Copied from” – you don’t even need to put
* in a “Copied from” if you copied an existing dissector, especially
* if the bulk of the code in the new dissector is your code)
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software
* Foundation, Inc., 59 Temple Place – Suite 330, Boston, MA 02111-1307, USA.
*/
Add your includes
The next portion of the template defines includes for the dissector. Those includes are needed for global functions called from this dissector. Wireshark defines a number of global functions that can be used within your protocol dissector. Of course, you may need to add some standard header files from your compiler or standard library.
#include “config.h”
#ifdef HAVE_SYS_TYPES_H
#include <sys/types.h>
#endif
#include <sys/stat.h>
#include
#include
#include <epan/packet.h>
#include <epan/prefs.h>
#include <epan/expert.h>
#include “packet-lwm.h”
The following list displays some of the most common includes that define the global functions that might be needed by your dissector:
- prefs.h Structure and functions for manipulating system preferences.
- tap.h Functions for utilizing the built-in TAP interface.
- expert.h Structure and functions to call the expert TAP.
- epan/column-info.h Structure of Summary window column data.
- epan/framedata.h Structure of frame data.
- epan/packet-info.h Structure of packet information.
- epan/value_string.h Functions to locate strings based on numeric values.
Register the protocol with Wireshark
This step describes the function which register the protocol dissector with Wireshark.
/* Register the protocol with Wireshark
/* this format is required because a script is used to build
/* the C function that calls all the protocol registration.
*/
void proto_register_PROTOABBREV(void)
{
/* Setup list of header fields */
static hf_register_info hf[] = {
{ &hf_PROTOABBREV_FIELDABBREV,
{ “FIELDNAME”,
“PROTOABBREV.FIELDABBREV”,
FIELDTYPE, FIELDBASE, FIELDCONVERT, BITMASK, “FIELDDESCR” }
},
};
/* Setup protocol subtree array */
static gint *ett[] = {
&ett_PROTOABBREV,
};
/* Register the protocol name and description */
proto_PROTOABBREV = proto_register_protocol(“PROTONAME”, “PROTOSHORTNAME”, “PROTOABBREV”,HFILL);
/* Required function calls to register the header fields and subtree used */
proto_register_field_array(proto_PROTOABBREV, hf, array_length(hf));
proto_register_subtree_array(ett, array_length(ett));
}
The first part of the proto_register_myprot function sets up the hf array fields of the dissection. Although, these are not required for packet dissection, they are recommended to take advantage of the full-featured display filter capabilities of the Wireshark software. Each item that is defined within the hf array will be an individual item that can be filtered within Wireshark.
The next part of the registration process is to define the array for the subtree called ett.The ett variables keep track of state of the tree branch in the GUI protocol tree (e.g., whether the tree branch is open [expanded] or closed). The protocol is registered with both short and long naming conventions within Wireshark by calling the proto_register_protocol function (this causes the protocol to be displayed in the Wireshark’s Enabled Protocols window). The final step is to register the hf and ett arrays with the proto_register_field_arry and the proto_register_subtree_array.
- PROTONAME The name of the protocol; this is displayed in the top-level protocol tree item for that protocol.
- PROTOSHORTNAME An abbreviated name for the protocol; this is displayed in the “Preferences” dialog box if your dissector has any preferences, in the dialog box of enabled protocols, and in the dialog box for filter fields when constructing a filter expression.
- PROTOABBREV A name for the protocol for use in filter expressions; it shall contain only lower-case letters, digits, and hyphens.
- FIELDNAME The displayed name for the header field.
- FIELDABBREV The abbreviated name for the header field. (NO SPACES)
- FIELDTYPE FT_NONE, FT_BOOLEAN, FT_UINT8, FT_UINT16, FT_UINT24, FT_UINT32, FT_UINT64, FT_INT8, FT_INT16, FT_INT24, FT_INT32, FT_INT64, FT_FLOAT, FT_DOUBLE, FT_ABSOLUTE_TIME, FT_RELATIVE_TIME, FT_STRING, FT_STRINGZ, FT_EUI64, FT_UINT_STRING, FT_ETHER, FT_BYTES, FT_UINT_BYTES, FT_IPv4, FT_IPv6, FT_IPXNET, FT_FRAMENUM, FT_PROTOCOL, FT_GUID, FT_OID
- FIELDDISPLAY
- For FT_UINT{8,16,24,32,64} and FT_INT{8,16,24,32,64): BASE_DEC, BASE_HEX, BASE_OCT, BASE_DEC_HEX, BASE_HEX_DEC, or BASE_CUSTOM, possibly ORed with BASE_RANGE_STRING or BASE_EXT_STRING
- For FT_ABSOLUTE_TIME: ABSOLUTE_TIME_LOCAL, ABSOLUTE_TIME_UTC, or ABSOLUTE_TIME_DOY_UTC
- For FT_BOOLEAN: if BITMASK is non-zero: Number of bits in the field containing the FT_BOOLEAN bitfield.
- For all other types: BASE_NONE
- FIELDCONVERT VALS(x), RVALS(x), TFS(x), NULL
- BITMASK Used to mask a field not 8-bit aligned or with a size other than a multiple of 8 bits
- FIELDDESCR A brief description of the field, or NULL. [Please do not use “”].
- PARENT_SUBFIELD Lower level protocol field used for lookup, i.e. “tcp.port”
- ID_VALUE Lower level protocol field value that identifies this protocol For example the TCP or UDP port number
Code example for our LWM dissector:
static int hf_lwm_fcf = -1;
static int hf_lwm_fcf_ack_req = -1;
static int hf_lwm_fcf_security = -1;
static const value_string lwm_cmd_names[] = {
{ 0x00, “Acknowledgment frame” },
{ 0x01, “Route Error” },
{ 0, NULL }
};
…
void proto_register_lwm(void)
{
static hf_register_info hf[] = {
{ &hf_lwm_fcf,
{ “Frame control field”, “lwm.fcf”, FT_UINT8, BASE_HEX, VALS(lwm_fcf_names), 0x0,
“Control information for the frame.”, HFILL }},
{ &hf_lwm_fcf_ack_req,
{ “Acknowledgment Request”, “lwm.ack_req”, FT_BOOLEAN, 8, NULL, 0x80,
“Whether an acknowledgment is required from the destination node.”, HFILL }},
…
}
/* Subtrees */
static gint *ett[] = {
&ett_lwm,
&ett_lwm_cmd_tree
};
/* Register protocol name and description. */
proto_lwm = proto_register_protocol(“Lightweight Mesh”, “LwMesh”, “lwm”);
/* Register header fields and subtrees. */
proto_register_field_array(proto_lwm, hf, array_length(hf));
proto_register_subtree_array(ett, array_length(ett));
/* Register dissector with Wireshark. */
register_dissector(“lwm”, dissect_lwm, proto_lwm);
- static int hf_lwm_fcf = -1; You should set each variable to default value -1.
- static const value_string lwm_cmd_names[] =… This string array is used for field, in case that you want assign label for values. Array must have last item { 0, NULL }. Then you need to apply VALS(lwm_fcf_names) in hf_register_info.
- hf_lwm_fcf is LWM protocol packet types. It is a 8 bit field and we assign the labels from lwm_fcf_name to it.
- hf_lwm_fcf_ack_req this is flag (FT_BOOLEAN) of Ack Request located in the LWM FCF field.
- HFILL macro at the end of the struct will set default values for internally used fields.
- *ett[] – is an array for every tree or subtree.
Link Dissector to Wireshark
How could the Wireshark know when to pass the data stream from a specific type of packet to our new dissector? Wireshark requires from each dissector when it should be called. For example, suppose you have a dissector which decode packets that are transported on the top of TCP on port 250. So how to instruct Wireshark to pass all packets that meet this criteria to your new dissector?
void proto_reg_handoff_PROTOABBREV(void)
{
dissector_handle_t PROTOABBREV_handle;
PROTOABBREV_handle = create_dissector_handle(dissect_PROTOABBREV, proto_PROTOABBREV);
dissector_add(“PARENT_SUBFIELD”, ID_VALUE, PROTOABBREV_handle);
}
The proto_reg_handoff_xxx function is the answer. The create_dissector_handle function passes the function that Wireshark will call to dissect the packets and the proto_xxx value that was registered as the protocol in the proto_register_protocol function.The dissector_add function allows you to specify the criteria when the data are forwarded to your dissector. The PARENT_SUBFIELD allows you to specify the element or trigger within the parent dissector e.g. for TCP port 250, you would set this value to tcp.port and ID_VALUE to 250. Wireshark then automatically forwards data to your dissector by calling the function defined in create_dissector_handle if the value of tcp.port equals 250.
Also note that PARENT_SUBFIELDs are named similar to hf fields, but they are not the same.The PARENT_SUBFIELDS are values that are exported by parent dissectors to allow link with the next dissector (e.g., there is a value ethertype that is a PARENT_SUBFIELD, but it does not follow the pattern of being named after an hf field).
Example of dissector handler, triggered by TCP on port 250:
void proto_reg_handoff_myprot(void)
{
dissector_handle_t myprot_handle;
myprot_handle = create_dissector_handle(dissect_myprot, proto_myprot);
dissector_add(“tcp.port”, 250, myprot_handle);
}
Heuristic Dissector Link to Wireshark
While the Wireshark starts, heuristic dissectors (HD) register themselves slightly different than the standard dissectors. Basically each HD can ask for any TCP packet therefore more than one HD can exist for the TCP packet.
Firstly, Wireshark decodes TCP packet data and tries to find a dissector registered directly for related TCP port.
In case of heuristic dissector it looks into the first few packet bytes and searches for predefined patterns. Most of the protocols starts with a specific header, so a specific pattern may look like (synthetic example):
- first byte must be 0×42
- second byte is a type field and can only contain values between 0×20 – 0×33
- third byte is a flag field, where the lower 4 bits always contain the value 0
- fourth and fifth bytes contain a 16 bit length field, where the value can’t be larger than 10000 bytes
Our heuristic dissector will parse incoming packet data check all the conditions above. If all of the four conditions are met there is a good chance that the packet really contains the expected protocol and dissector may decode rest of the incoming packet.
static gboolean dissect_PROTOABBREV(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree)
{
/* 1) first byte must be 0x42 */
if ( tvb_get_guint8(tvb, 0) != 0x42 )
return (FALSE);
/* 2) second byte is a type field and only can contain values between 0x20-0x33 */
if ( tvb_get_guint8(tvb, 1) < 0x20 || tvb_get_guint8(tvb, 1) > 0x33 )
return (FALSE);
/* 3) third byte is a flag field, where the lower 4 bits always contain the value 0 */
if ( tvb_get_guint8(tvb, 2) & 0x0f )
return (FALSE);
/* 4) fourth and fifth bytes contains a 16 bit length field, where the value can’t be longer than 10000 bytes */
/* Assumes network byte order */
if ( tvb_get_ntohs(tvb, 3) > 10000 )
return (FALSE);
/* Assume it’s your packet and do dissection */
return (TRUE);
}
It is also possible to write a dissector which is hybrid heuristic/normal.
void proto_reg_handoff_PROTOABBREV(void)
{
static int PROTOABBREV_inited = FALSE;
if ( !PROTOABBREV_inited )
{
/* register as heuristic dissector for both TCP and UDP */
heur_dissector_add(“tcp”, dissect_PROTOABBREV, proto_PROTOABBREV);
heur_dissector_add(“udp”, dissect_PROTOABBREV, proto_PROTOABBREV);
}
}
Let’s get back to our LWM dissector. Example of heuristic handle for LWM dissector have only an one condition. First byte have to have 6 lower bits set to 0. If condition is accomplished, it is called function dissect_lwm.
This is example for our LWM dissector:
static gboolean dissect_lwm_heur(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree)
{
/* 1) first byte must be xx000000 */
if (tvb_get_guint8(tvb, 0) & 0x3F)
return (FALSE);
dissect_lwm(tvb, pinfo, tree);
return (TRUE);
}
…
void proto_reg_handoff_lwm(void)
{
/* Register our dissector with IEEE 802.15.4 */
heur_dissector_add(“wpan”, dissect_lwm_heur, proto_lwm);
}
Getting data from the packet
To get data from the packet tvb_get_xxx function can be used.
guint request_reply;
guint offset = 0;
request_reply = tvb_get_guint8(tvb, offset);
This code extracts first byte from the packet. The tvb (tvbbuff) parameter tells Wireshark the length of the data to highlight in the Wireshark’s hex display window when this value is selected in the Wireshark’s Decode window. Also note that the tvbuff starts at the beginning of the data passed to your dissector. Offset parameter is location in your dissector in bytes.
There is a many functions tvb_get for extraction data. You should read README.developer, where are examples of functions for 8-bits, 16-bits 32-bits, 64-bits, Network-to-host-order , for IPv4 and IPv6 addresses and more.
Displaying the data
For the data display function proto_tree_add_xxx is used. There are several functions available for programmer which can display either protocol or field label:
proto_item *proto_tree_add_item(tree, id, tvb, offset, length, encoding);
proto_tree_add_item is used when you do not need some special formatting. The item is added to the GUI tree with its name and value.
- tree where the item is to be added.
- id is the hf_PROTOABBREV_FIELDABBREV field which is registered in register_info.
- tvb The tvbuff to mark as the source code data.
- offset The offset in the tvb where the data is located.
- length the length of the value (in bytes) in the tvb.
- encoding the data value displayed via the printf format.
The proto_tree_add_uint function can be used to display the data already stored in the request_reply variable. If the value had not already been stored in a variable, the proto_tree_add_item function would be the most efficient to use.
// displaying text
proto_item *proto_tree_add_text(tree, tvb, start, length, format, …);
// displaying bit fields
proto_item *proto_tree_add_boolean(tree, id, tvb, start, length, value);
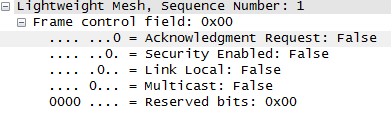
Let’s make some example. In the LWM protocol we would like to parse FCF bit field and display meaningful label for ACK request bit:
…
proto_tree_add_boolean(lwm_tree, hf_lwm_fcf_ack_req, tvb, 0, 1, lwm_fcf_ack_req);
…
{ &hf_lwm_fcf_ack_req,
{ “Acknowledgment Request”, “lwm.ack_req”, FT_BOOLEAN, 8, NULL, 0x01,
“Whether an acknowledgment is required from the destination node.”, HFILL }},
Example of displaying bit field in Wireshark:
Summary info
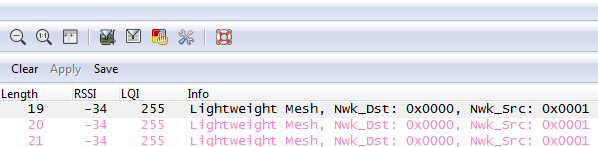
Wireshark has Summary window so-called Info which allows to browse important information without having to look at each packet in detail. You can add info similar like printf function. Here is and example:
if(check_col(pinfo->cinfo, COL_INFO)) {
col_clear(pinfo->cinfo, COL_INFO);
col_add_fstr(pinfo->cinfo, COL_INFO,”Lightweight Mesh, Nwk_Dst: 0x%04x, Nwk_Src: 0x%04x”,lwm_dst_addr,lwm_src_addr);
}
Let’s see the result in Info column: